|
Hüpoteeside kontroll |
| Kahe üldkogumi dispersioonide võrdlemine - F-test Et üldjuhul võrreldakse kahe üldkogumi keskväärtusi omavahel omamata mingit eelinformatsiooni dispersioonide kohta, tuleks hüpoteeside kontrolli alustada kahe üldkogumi dispersioonide erinevuse selgitamisega. St., enne t-testi juurde asumist tuleks kontrollida hüpoteeside paari H0 : kus MS Excel võimaldab sellist kahepoolset
hüpoteesi kontrollida funktsiooni
Tulemuseks väljastatakse eelnevalt kursoriga määratud lahtrisse olulisuse tõenäosuse p väärtuse. Kui leitud p < 0,05, võib lugeda tõestatuks hüpoteesi H1, st. et varieeruvus kahes võrreldavas üldkogumis on erinev olulisuse nivool 0,05. Võrreldes näiteks mannaputru armastavate ja seda mittearmastavate tudengite kehakaalude varieeruvust, saame olulisuse tõenäosuseks p = 0,37. Kuna 0,37 > 0,05, siis ei õnnestu meil tõestada kehakaalude varieeruvuse erinevust.
|
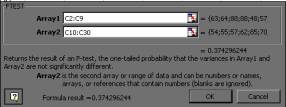
|
|
|
Hüpoteesi esimese üldkogumi suuremast
varieeruvusest (H1: Protseduuri tellimisaknas
tuleb täita järgmised väljad: Protseduur väljastab tabelina järgmised suurused
Juhul, kui arvuti poolt väljastatud
olulisuse tõenäosus p < 0,05 (0,01; 0,001), võime
vastaval olulisuse nivool väita, et varieeruvus esimeses
kogumis on suurem kui teises, vastasel juhul oleme sunnitud
konstateerima, et ei õnnestunud tõestada uuritava tunnuse
suuremat varieeruvust esimeses grupis. |
|
|
ktanel@eau.ee
http://ph.eau.ee/~ktanel/kool_ja_too/
märts, 2000